Describe the issue:
I am trying to validate a field to only allow lowercase values. This is to help content maintainers create data that works as expected downstream. The value is an ID of sorts. It may contain uppercase characters in the source system A where the content maintainer copies the value from, but the value in Dato must not contain any uppercase characters so that the ID works properly in system B. We are in an intermediary phase and trying to move away from this pattern, but it will take some time. To make it easier for content maintainers to remember this data requirement, we’d like to implement a validation that only allows lowercase letters.
(Optional) Do you have any sample code you can provide?
await client.fields.update('model::field', {
validators: {
format: {
custom_pattern: '^(?!.*p{Lu}).*$',
},
},
});
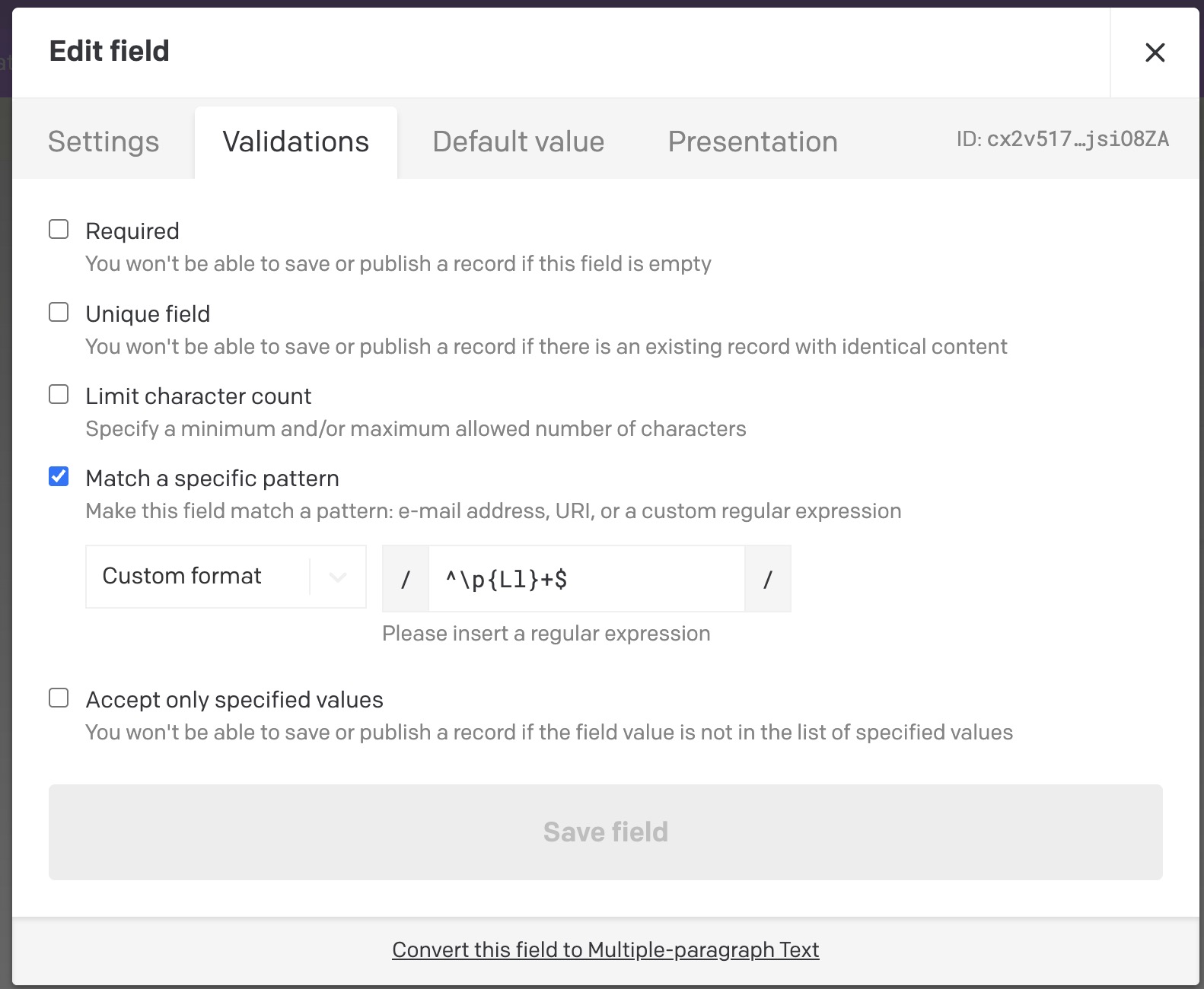
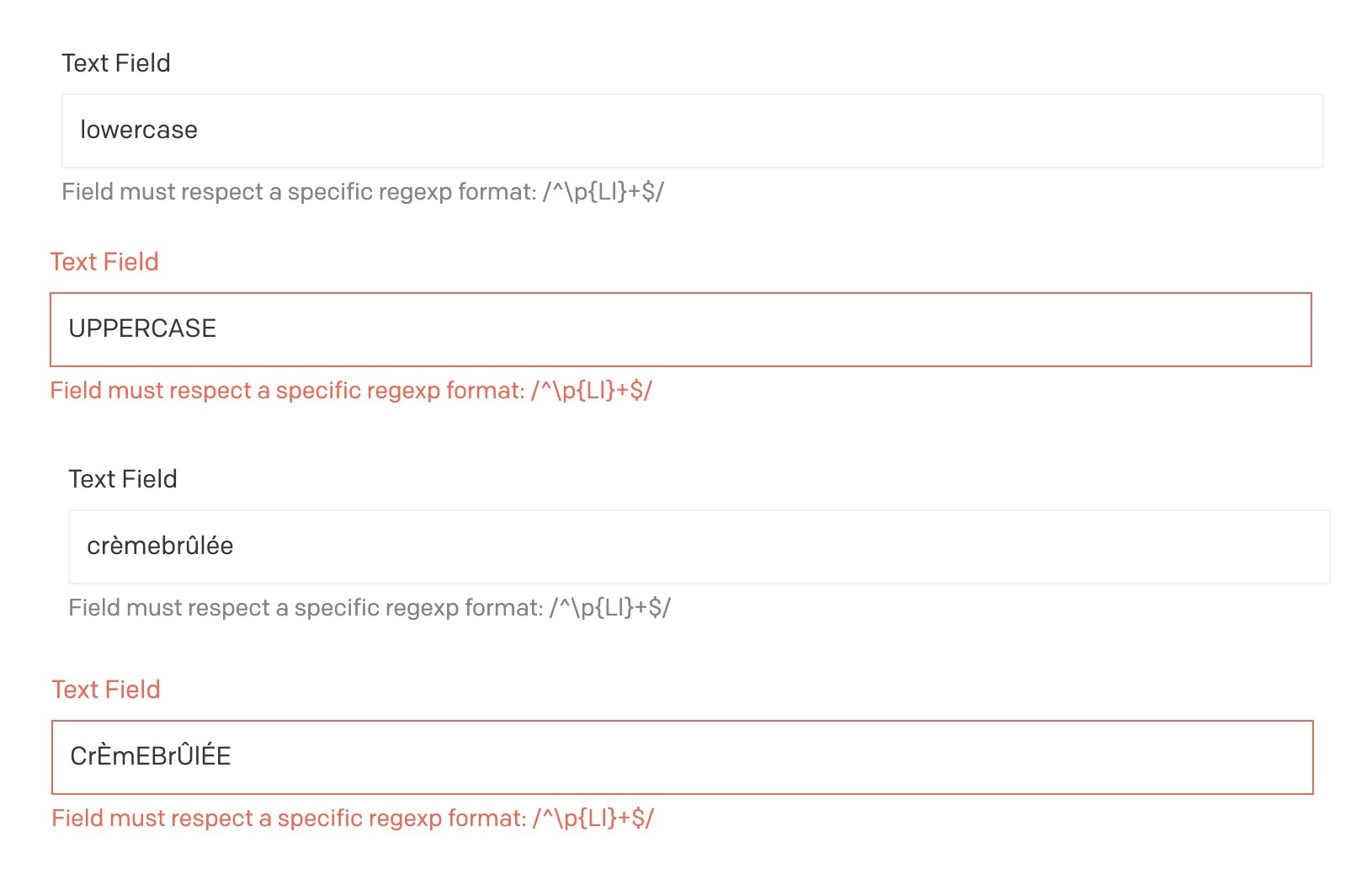
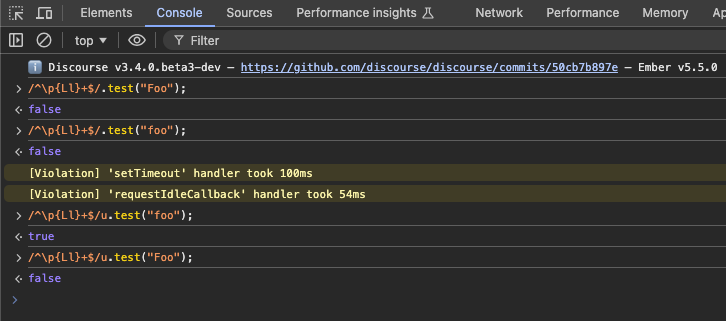
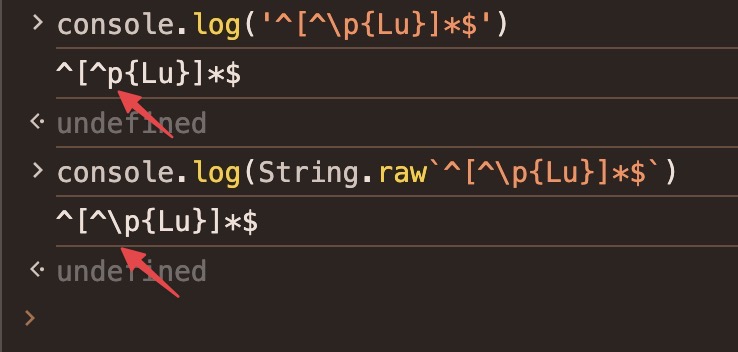
I have attempted to use the Lu unicode category to create a match that disallows all uppercase characters in the alphabets that are relevant to the project. This works in principle, but I don’t think that I can make it work with Dato as it appears the regex is tested with JS in which case I would need to provide the u regex flag in order to get this match to behave correctly.
Another option could be to list all other uppercase characters that can’t be covered with A-Z, but it seems like an unfortunate amount of special cases to maintain:
^(?!.*[A-ZÀÁÂÃÄÅÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝĀĂĄĆĈĊČĎĐĒĔĖĘĚĜĞĠĢĤĦĨĪĬĮİĴĶĹĻĽĿŁŃŅŇŊŌŎŐŒŔŖŘŚŜŞŠŢŤŦŨŪŬŮŰŲŴŶŸŹŻŽ]).*$
It would be nicer if I could offload all of that thinking to unicode categories and the knowledgeable people who have worked to create them.
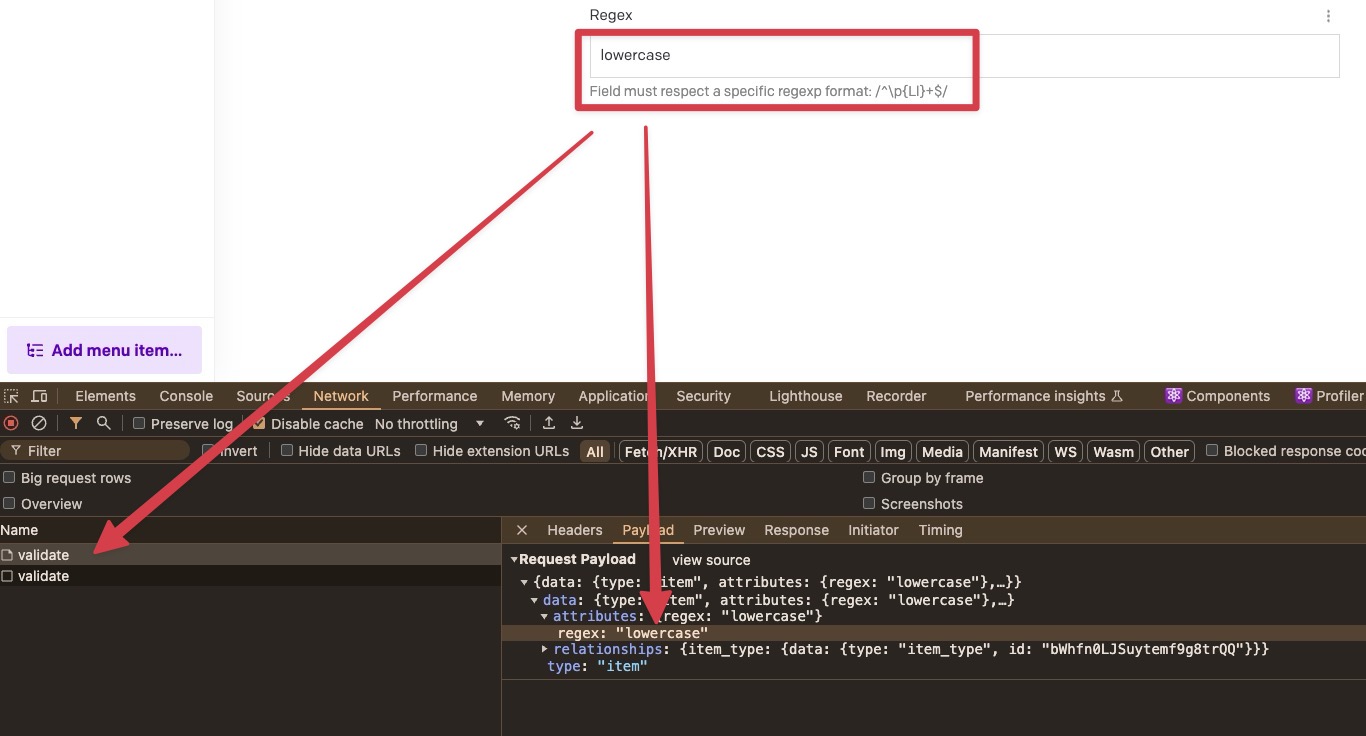
The UI will also display this quite complex and technical pattern. It may seem suspicious to people without a technical background.
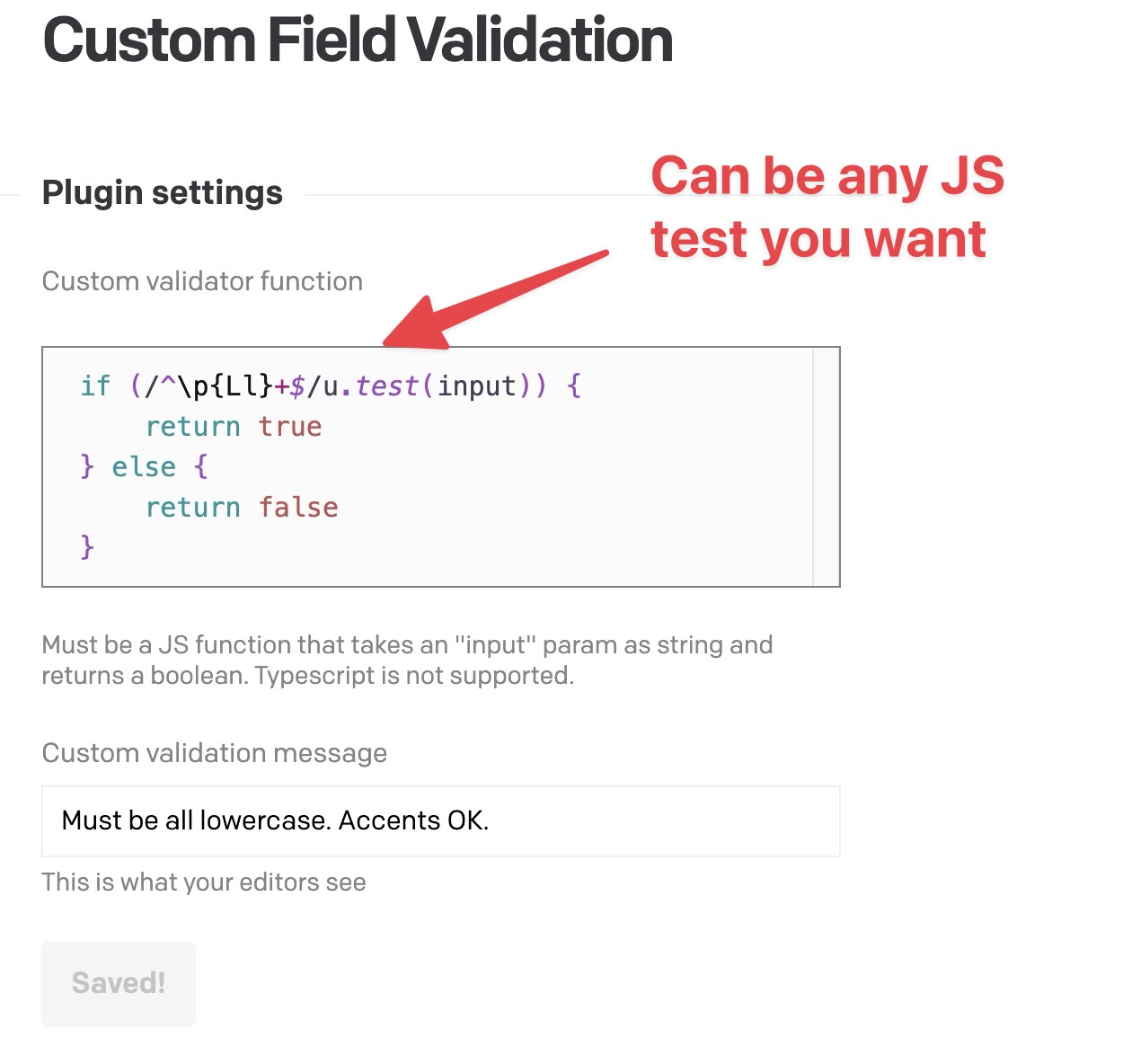
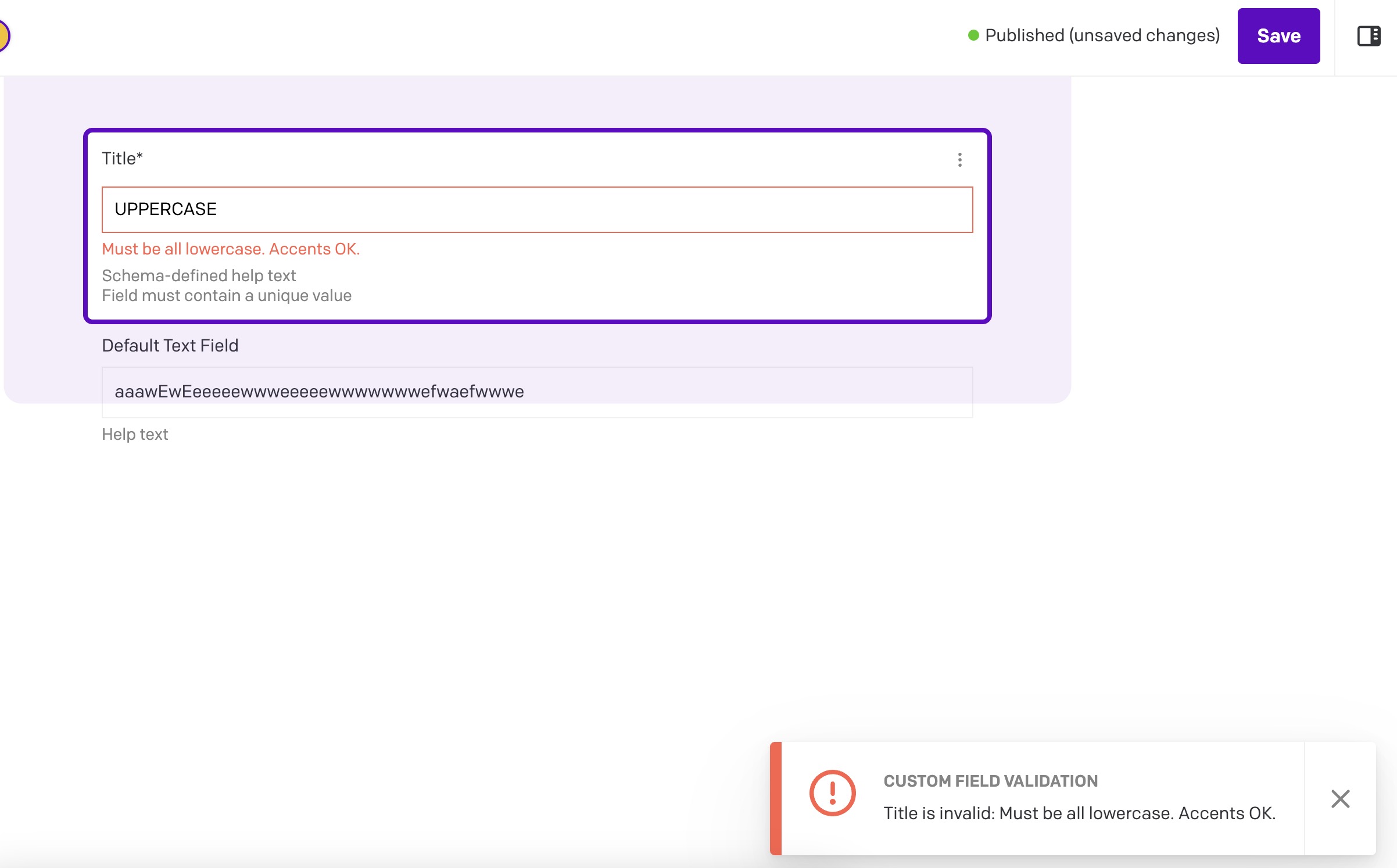
As there don’t seem to be other questions about this topic, I am wondering whether I’ve missed some more idiomatic way to ensure data quality in a case like this.