Hey @Chris_Richards,
Can you please log the exact request & response chain from Curl and send it to us at support@datocms.com (or DM us here, or post it publicly after stripping the credentials)? It’s hard to troubleshoot this without seeing the exact payload going over the wire.
I suspect that what’s going on is that the AWS presigned URL from step 1 isn’t getting sent to S3 correctly. That signed URL has nothing to do with your Dato tokens, but is rather a single-use secret generated by S3 (in step 1) to allow you to PUT a file directly to them – entirely outside of Dato. It’s a secret token that you send as part of the URL query string.
Once that file is successfully uploaded to S3, step 3 just “associates” it with a upload record inside Dato. The 404 not found for a job request means it’s still processing (as documented in step 4), so you could keep polling until it 200s or just ignore it and wait a few seconds.
In a bit more detail…
Please make sure the attributes.url from Step 1’s response is being used, in its entirety, for PUTing the image to S3. It should look something like this:
https://datosrl-images.s3.eu-west-1.amazonaws.com/150894/1738359901-filename.png?x-amz-acl=private&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=SECRET%2F20250131%2Feu-west-1%2Fs3%2Faws4_request&X-Amz-Date=20250131T214501Z&X-Amz-Expires=900&X-Amz-SignedHeaders=host&X-Amz-Signature=SIGNATURESTRING
If you then PUT the image to S3 and get back a 200 with an empty body, that’s totally normal (as Marcelo said).
Then in step 3, you need to send a body like:
{"data":{"type":"upload","attributes":{"path":"/150894/1738359901-screenshot-000977.png"},"relationships":{}}}
Where the path is the data.id from Step 1’s Dato response (not step 2 from AWS)
If that went through right, you should get a 202 Accepted, not a 200.
Then if you poll for the job result, it will 404 until it completes, but you don’t really need to worry about that. The image should just show up in the media area after a few seconds. If it doesn’t, something is failing along the way, but it’s hard to say what exactly without seeing your exact requests & responses.
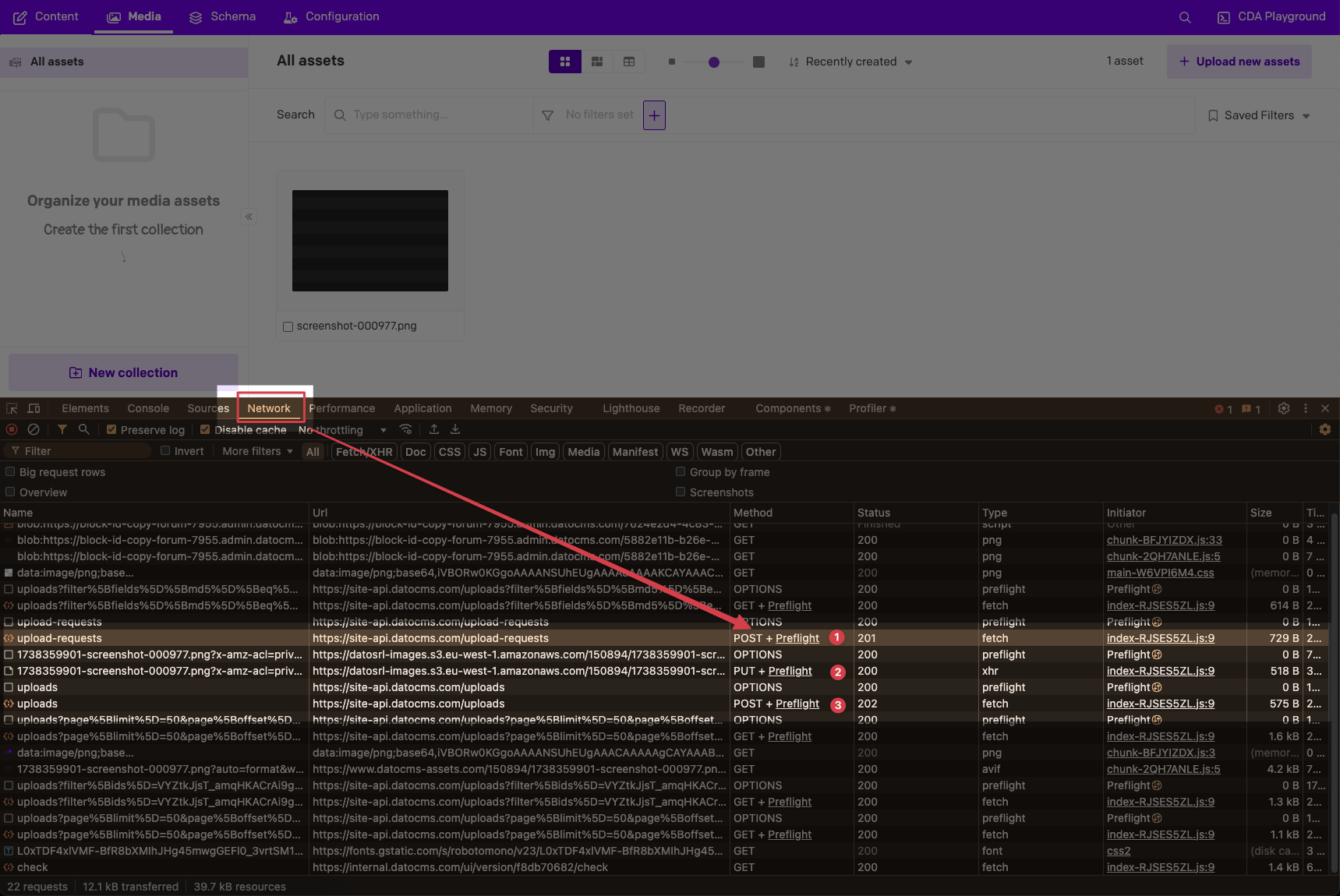
Also, if you go to the media area in your project and open the browser’s network inspector and then try to upload an image, you can see the exact requests & responses being sent. The media area does it the same way our client does, or the way you would if you were uploading via raw HTTP. If you right-click an entry and copy it as curl, you can re-use that request elsewhere and compare it to what you have now.
In the inspector:
- Step 1 would be a
POST to https://site-api.datocms.com/upload-requests
- Step 2 would be a
PUT to https://datosrl-images.s3.eu-west-1.amazonaws.com/ (or step’s URL)
- Step 3 would be a
POST to https://site-api.datocms.com/uploads
- (I think we skip step 4 in the media area and instead just refresh the list of uploads)