When using a slug in a tree-like collection the slug should represent the structure.
I think, if a slug field is added to a model in a tree collection, it makes the most sense to let the slug represent the collection. This way you are able to let editors nest pages and get the content structure they expect from the CMS.
I know Dato is also used for many other cases than websites, but I also think when slugs are used they are mainly targeted websites.
@mads our approach here is to use the slug as an identifier only for the record, not for the entire tree. As you might want to reorder your structure and change your URL accordingly.
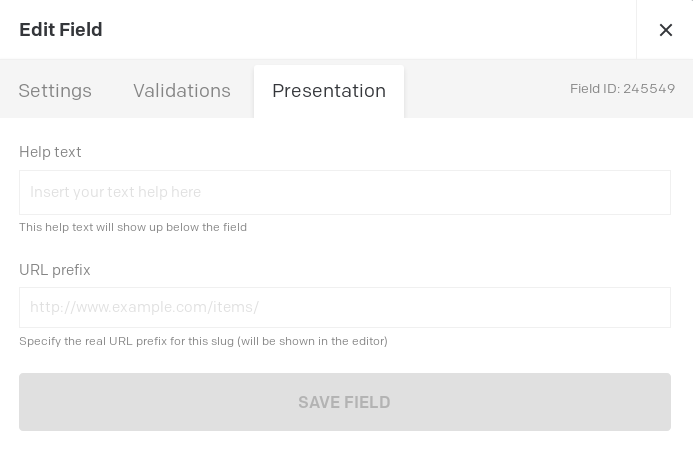
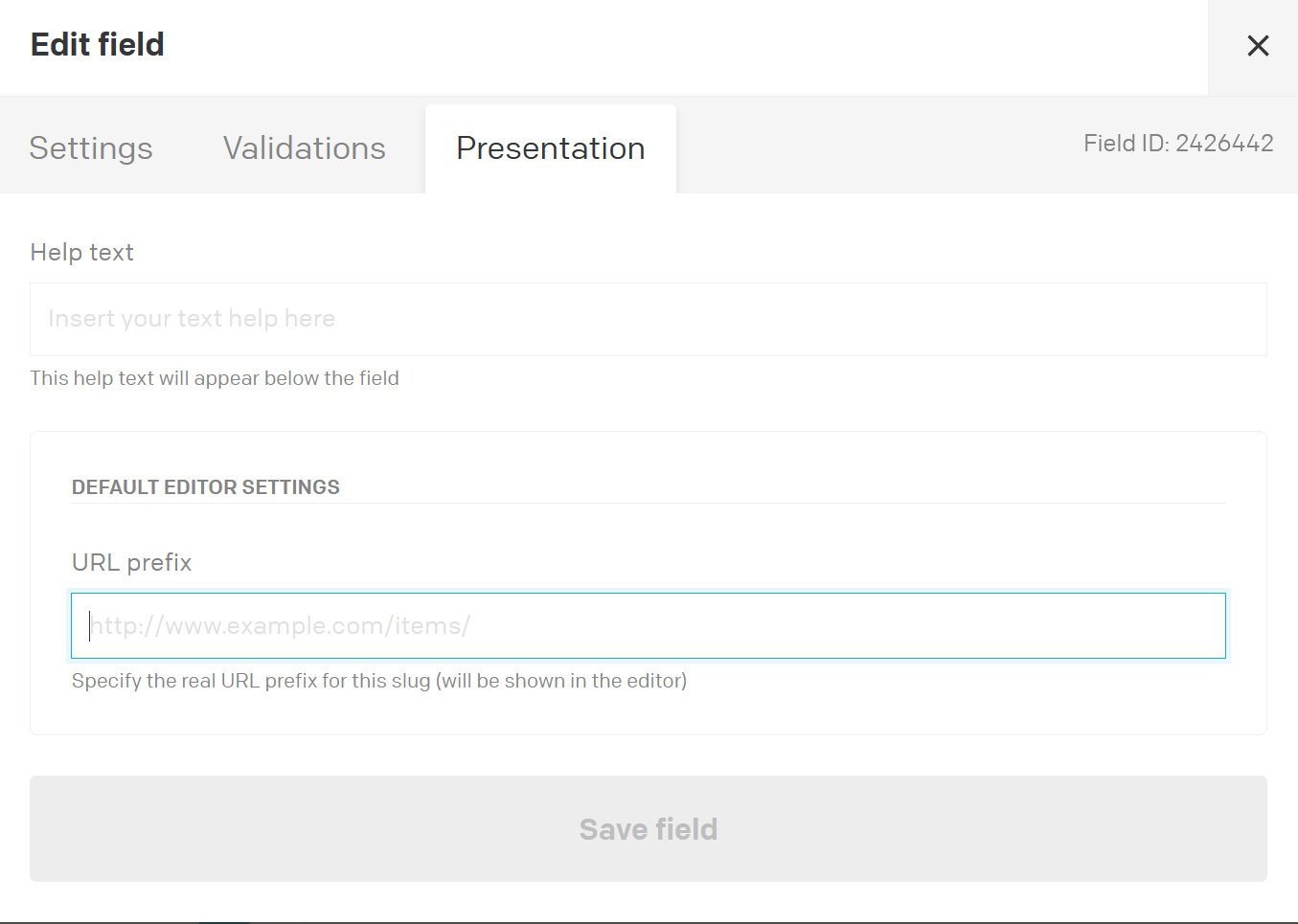
What you can do to help your editors is to change what you present in the interface here:
We’ve made a plugin, which builds URL from the slug of the parent record and the current record ({parent_slug}/{current_slug}). You can find it here: https://github.com/SYMBIO/datocms-plugin-tree-url. Feel free to fork it.
hey @max.c this has not changed recently, but to me you should fetch all the slugs locally and build your slug structure on your frontend, what do you think?
Hey @mat_jack1 , that’s great, but then the slug field in the UI would not show the real URL structure anymore. On the screenshot I attached it would be great if after https://example.com/ the slugs of the parent pages were available dynamically. For instance, https://example.com/wealth would be in the grey area, if the wealth page were the parent of investment.
The prefix is static yes, it doesn’t solve the issue for trees actually. It can help, but it doesn’t do everything you need.
The only solution would be to use a plugin that fetches the full URL from your frontend, so that you get maximum flexibility and correct information on the full URL. I know it’s a bit convoluted, but the routing of your frontend is something that we don’t manage, so it would be a bit strange to show the full structure when it could be handled differently in the frontend.
Sometimes, the opposite could be better. That the CMS construct the structure. Then the slug field could be an unique id for the entire path. Ex we could use that to fetch the correct record. Ex from below would be if we has a slug field (that gets generated automatically based on parent pages slug fiels) contains about-us/offices/london (but you can only edit the last slug london on the child page).
Alt that it’s possible to filter in GraphQL based in parent fields (and also retrieve selected parent pages fields like slug in ctx.plugin.attributes for plugins). This is a very specific for sites that. So understand it’s not optimal when there is no slug fields. But I guess a big use-case for Dato is site building anyway. But will try to breakdown the problem and usecase below:
Ex page hierarcy in Dato( with the field slug written out as a graph)
(maybe not the best fictional example, but it illustrates the problem)
about-us
├ london
└ offices
├ london
├ gothenburg
└ tunis
london
Ex full slugs:
/about-us
/about-us/london
/about-us/offices
/about-us/offices/london
/about-us/offices/gothenburg
/london
Problem:
Can’t visualize the full slug in dato CMS for things like preview buttons to front-end, SEO previews or slug fields.
When fetching in front-end, we need to fetch based on the parent slug’s too, else we could get the wrong page, as there are two records with the slug london. This is not possible as the GraphQL filter doesn’t allow to filter for a parent page’s slug, only for the records id or to check if it “exists”.
Potential workarounds:
Create a new model for each subpage (but will not work when the editor wanna create it’s own parent pages)
Fetch data about parent, and it’s parent and it’s parent recursivity all way down in front-end to retrieve to be able to construct the full relative slug
To fetch the correct page in front-end, check if the browser slug contains multiple slugs, then in GraphQL query, check if the current page has a parent page attached to it, and then assume it’s the correct record. Note, will not always return correct data. See example below:
Question:
User visits the page /about-us/london. What record should we return?
Pitfalls: This could return the wrong record if there is multiple child records with the same slug but with different parents. As with above where there is two records with slug london but with different parent pages.
Example workaround 2:
Fetch all pages with the slug london. Map through them to see if any has a parent. Make another couple requests to see if anyone of them has the parent slug.
I agree with Dato’s approach that the slug should only act as an identifier and not represent a path. These are two very different things and should not be mixed.
We’ve managed working with tree like collections and coding a path generator based on the graphql query (ie: NextJS project with SSG only). This code lies within the project and not within the CMS. It works well with preview and on-demand isr.
The main tricky point with on-demand isr is: how to make sure that /foo/bar is not equal to /bar, which is not equal to /bla/bar, based on the slug only?
Solution: on every client request, we try to retrieve the record through the graphql API filtering the request with the slug. If no record is found, easy, we return a 404. If a record is found, then we generate a path based on the props that we just received, which contains the parent information (which is all we need to generate a tree based path + the slug of course). Then we compare it to the path requested by the client. If there’s a match, then the page is built/revalidated, if there’s no match, then we return a 404.
Example:
client requests /foo/bar
we take “bar”, retrieve the record
based on the parent(s) declared within the record, we generate the following path recursively (no need for additional API call, you get all you need from the very first call): /bam/foo/bar
we compare /foo/bar to /bam/foo/bar = no match
we return a 404
@m.finamor
Thank you so much! I couldn’t get it to work with localization activated on the field. Do you think you could update it so that it’d work with localized slug?